Archive for the ‘WHATWG’ Category
Monday, October 14th, 2013
Today we're happy to add two more specs to the WHATWG stable, Books and Figures! These are specifications focused on CSS features. Books provides ways to turn HTML document into books, either on screen or on paper. Using Books, authors can style cross-references, footnotes, and most other things needed to present books on screen or paper. Figures are also based on traditional publishing — it provides ways to float elements with respect to columns and pages, and describes how to wrap text around them.
Printing was part of the first CSS proposal in 1994, and many of these CSS features have been in use since the first paper book written in HTML and CSS (CSS — Designing for the Web) was published in 2005. Now, a decade later, bestsellers are routinely produced with CSS. There are currently two implementations of these specifications that are able to produce books: AntennaHouse and Prince. We hope that our continued work on these specifications will help existing implementations converge, and also encourage browsers to present web content as pages. Pages can be printed, stored as PDF files, or shown on screens. Many users will prefer pages to scrollbars, and these specifications will help make it happen.
As an example of a feature from Books, consider footnotes. Turning an element into a footnote is easy:
span.footnote { float: footnote }
This can, with a few more styles, be formatted as:
![Body text, with a superscripted footnote saying '[1]' in red, and under the body, a short line delimiting the body from text in a smaller font size, with the same red '[1]' indicating the footnote.](//people.opera.com/howcome/2013/whatwg/books/footnotes.png)
In another example, common newspaper and magazine layouts can be achieved with just a 10-line style sheet. Here's what this could look like:
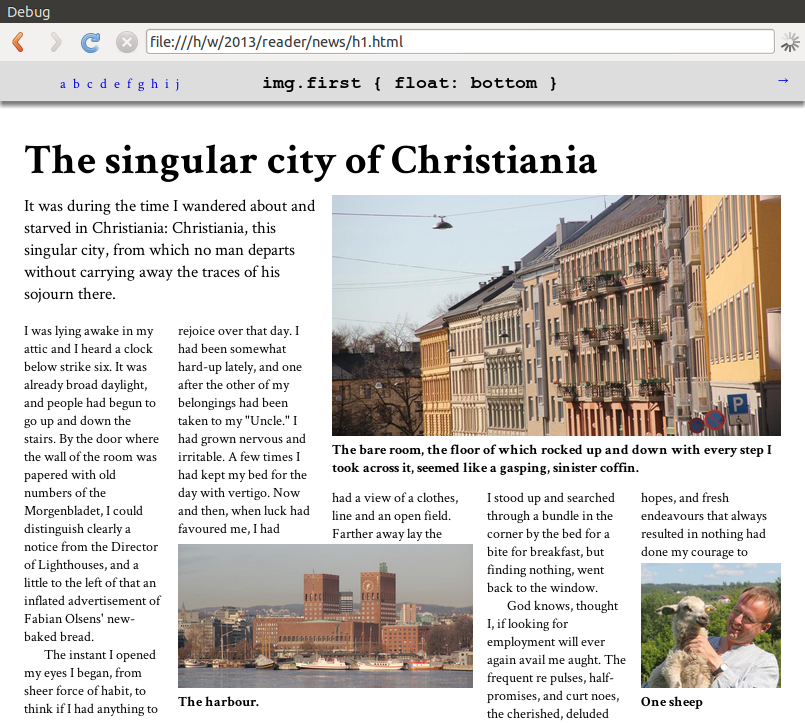
More screenshots and code examples are available.
Feedback on these specifications, like all our others, is most welcome, either on www-style, on WHATWG's mailing list, or as bugs in the bug database.
The features described by these specifications were previously published as part of a W3C CSS working group document that I wrote. Today we are moving the work to WHATWG, a W3C Community Group.
Posted in WHATWG | 6 Comments »
Friday, July 20th, 2012
In an email to the WHATWG mailing list Ian Hickson explained how the relationship between the WHATWG and W3C effort around HTML has evolved. It is recommended reading if you want to know the details.
In summary, we will remain focused on improving HTML and related technologies to address the needs of users, developers, and user agents. The W3C HTML WG has decided to focus on producing a snapshot: HTML5. We anticipate the net effect to be accelerated development of the HTML Living Standard.
Posted in W3C, WHATWG | 2 Comments »
Friday, June 8th, 2012
A new release of the Validator.nu HTML Parser is available. The new version 1.4 contains minor adjustments to spec compliance and fixes for notable Java-specific problems (of the crash and infinite loop sort). Also, the parser is again available from the Maven Central Repository (groupId: nu.validator.htmlparser, artifactId: htmlparser, version: 1.4).
Upgrading to the newest version is recommended for all users of all previous versions.
Changelog:
- No longer crashes in
setErrorHandler() in the DOM case.
- No longer crashes with
ArrayIndexOutOfBoundsException in the meta prescan.
- Correctness tweaks to HTML integration point and MathML text integration point behavior.
- Slight adjustments to error and warning reporting.
- The XLink namespace is now serialized more nicely.
- Unicode decoder returning zero-length output in the middle of the file is now dealt with correctly.
- No longer goes to infinite loop with the HotSpot workaround applied.
- Builds again with Maven.
Posted in WHATWG | 1 Comment »
Tuesday, April 24th, 2012
The WHATWG now has a patent policy, the WHATCG. We will keep using the same mailing list, the same IRC channel, the same web sites, but now sometimes we will publish through the WHATCG as well for patent policy purposes per the W3C Community Final Specification Agreement.
If you could previously not join the WHATWG because no patent policy was in place, now is the time to reconsider. If you are unsure how this applies to you, then it most likely does not.
Posted in W3C, WHATWG | Comments Off on Patent Policy
Wednesday, July 27th, 2011
(This is a cross-post from the mailing list, reformatted as HTML.)
Since February, I've been working on writing a detailed specification for browser editing, primarily the document.execCommand() and document.queryCommand*() methods. These were created by Microsoft in the 1990s and were subsequently adopted in some form by all other browsers, and today browsers have to implement them to be compatible with web content, but no detailed specification ever existed. Interoperability is practically nonexistent as a result, which has
driven all major content editing frameworks away from using execCommand(). (For instance, I began typing this in WordPress' WYSIWYG editor, which uses TinyMCE – a major editor that avoids execCommand() entirely.) Hopefully we can start to fix that and make these APIs a part of the web platform that just works.
The current version of the specification is about fifty pages printed, and supersedes the Editing APIs section of HTML (which is more like two pages). In the style of modern web specs, it
is phrased in terms of algorithms that attempt to cover all corner cases unambiguously and leave no behavior undefined, and it tries to match the behavior of existing browsers to the greatest extent possible. At this point, it's stable and complete enough that I believe it's ready for serious review by implementers, and I would like as much detailed feedback as possible.
There is a basically complete JavaScript implementation, which is used to produce expected results for a largely undocumented and entirely ad hoc test suite. I used the tests as an aid to writing the spec, and they probably aren't well suited to aid implementers in implementing it. I will probably get around to porting them to something like testharness.js at some point. I haven't tried testing my implementation on real-world sites, only on artificial input, so I don't know at this point how implementable it really is, but the JS implementation means that it at least has large parts that make sense.
Anyone reviewing the spec should be advised that I put extensive rationale in HTML comments. If you want to know why the spec says what it does, check the HTML source. I plan to change this to use <details> or such in the near future. There are lots of minor known issues still left, but none that I thought was important enough that it needs to delay review. Feedback can be sent to the whatwg list, CCing me, with [editing] in the subject. (I'm also fine receiving feedback on public-html or public-webapps, but I don't know if the chairs would be okay with that, since it's off-topic.) I should be available to respond to all feedback promptly at least through the end of August. After that, I can't make specific guarantees about my availability, but I do plan to continue maintaining the spec in the long term.
Posted in WHATWG | 3 Comments »
![Body text, with a superscripted footnote saying '[1]' in red, and under the body, a short line delimiting the body from text in a smaller font size, with the same red '[1]' indicating the footnote.](http://people.opera.com/howcome/2013/whatwg/books/footnotes.png)
